NAAC-Accredited 'A++' - Grade 2(f) & 12(B) status (UGC) |ISO
9001:2015 Certified | FIST Funded (DST) SIRO(DSIR)

Projects
Sponsored Projects Completed
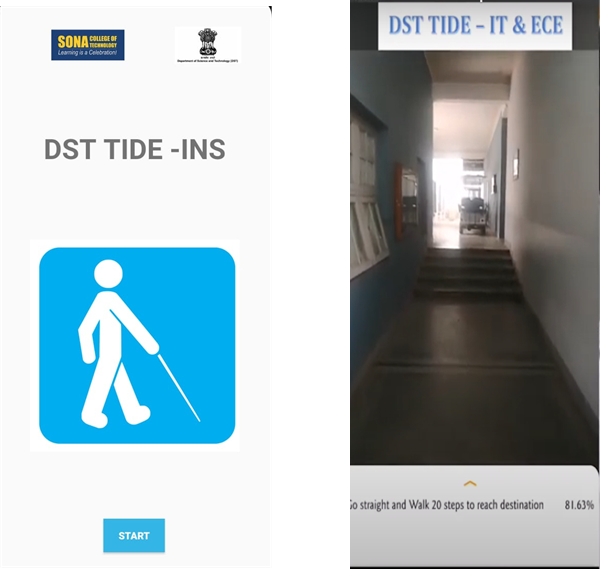
- “A proof of concept for indoor navigation using real time image recognition algorithm “, funded by DST-TIDE - Rs. 80,16,965 – (3 Years) - Dr. J. Akilandeswari, HOD & Professor).
- ICT Interventions to Promote Entrepreneurship Development of Women SHGs in Salem District, Tamil Nadu through Rural Agricultural Support Centers (Agri BPOs) , funded by DST-SEED - Rs. 56,35,204 – (3 Years) - Dr. J. Akilandeswari, HOD & Professor).
Projects completed
- Elimination of Redundant Association Rules – An Efficient Linear Approach – Dr. J. Akilandeswari
- Performance comparison of Machine Learning Algorithms that predicts students’ employability – Dr. J. Akilandeswari
- Analyzing Twitter Data to Identify Influential Factors in a Trending Topics – Dr. J. Akilandeswari
- SONA KNOW YOUR HALL Android App - Dr. J. Akilandeswari, A.Naveenkumar
- VeeTrace Mobile App - Dr. J. Akilandeswari, A.Naveenkumar
- Proof of Concepts for collecting the Health care data using block chain technologies - Dr. J. Akilandeswari, A.Naveenkumar
- TrackMySona- Dr. J. Akilandeswari, Mrs. D. Komalavalli, Mrs.I. Janani
- Knowledge Portal - Dr. J. Akilandeswari, Dr.P.Iyyanar, Mr.A.Naveenkumar
Projects ongoing
- Framework for disease surveillance system mining the social media data based on demographic data.
- Smart Attendance.
- Mark sheet Validation using Blockchain.
- Recognizing Indian sign language.
- IoT Shogi Board .
- Computer Vision Based Tree Stocking for forest Conservation.
- On Demand Provisioning of Infrastructure service to SONA students from pooled SONA Sources.